In all fairness, for any Arduino (or Atmel AVR) program it is hard to fathom a more authoritative source (on its behavior) than the list of machine instructions it ultimately compiles down to.
Disassemblers for viewing the contents of .HEX files (the end result of compilation that is typically flashed through the
bootloader on your Arduino) are not hard to come by. While the industry standard is definitely avr-objdump (in the avr-gcc toolchain), multiple people (including myself) wrote their own (you can find mine here).
Reading these disassembled listings can still be a laborious task (even more so when the code is generated by a compiler rather than manually assembled by a human programmer). The old adage “a picture is worth a thousand words” is true!
This blog post will focus on how to generate (basic) Control Flow Graphs, a computer science (code representation) primitive often attributed to have originated in the works of Frances E. Allen.
For this particular purpose (emitting graphs), generating our intermediate output in the DOT language
makes sense. On top of the fact that .DOT files are (1) easy to generate and (2) human readable and editable, the
Open Source GraphViz project libraries will make subsequent exports of these files to common formats easy
(SVG, PNG, JPG, …).
Potential practical applications can be found in abundance, from static code flow analysis that detects unreachable code to (automated or semi-automated) side channel timing attack vulnerability analysis.
A quick preview of the type of output we will be generating:
Disclaimer:
- Full accompanying source code for this blog post can be found on GitHub.
- Rather than being an exhaustive solution the code provided is an initial stab at the problem. In particular, not all branching statements (e.g.
IJMP) are supported. - The sources are C#, .NET Core so they should work cross-platform (Windows, Linux, Mac OSX).
Boilerplate for parsing Command Line Options
The great CommandLineParser library makes it extremely
simple to declaratively define (and subsequently parse) command line options. All that is required is something along these lines:
internal class Program
{
private static readonly Logger Logger =
LogManager.GetLogger(AVRControlFlowGraphGenerator.LoggerName);
private static void Main(string[] args)
{
Logger.Info("Parsing Command Line Arguments...");
Parser.Default.ParseArguments<CommandLineOptions>(args)
.WithParsed(options =>
{
var generationOptions = new AVRControlFlowGraphGeneratorOptions
{
InputFile = options.InputFile,
OutputFile = options.OutputFile,
StartAddress = options.StartAddress,
DPI = options.DPI
};
try
{
var generator =
new AVRControlFlowGraphGenerator(generationOptions);
generator.GenerateCFG();
Environment.Exit((int) ExitCode.Success);
}
catch (Exception ex)
{
Logger.Error(ex, $"Unexpected runtime error: {ex.Message}!");
Environment.Exit((int) ExitCode.RuntimeError);
}
})
.WithNotParsed(options =>
Environment.Exit((int) ExitCode.FailedToParseCommandLineArgs));
}
}using CommandLine;
namespace AVRControlFlowGraphGenerator
{
public class CommandLineOptions
{
[Option('i', "input", Required = true,
HelpText = "Input file (.HEX) for which to generate a CFG.")]
public string InputFile { get; set; }
[Option('o', "output", Required = true, HelpText = "Output file (.DOT).")]
public string OutputFile { get; set; }
[Option('s', "startaddress", Required = false, Default = 0,
HelpText = "Start Offset (defaults to 0x0).")]
public int StartAddress { get; set; }
[Option('d', "dpi", Required = false, Default = 200, HelpText = "DPI.")]
public int DPI { get; set; }
}
}Running the tool without parameters will then automagically report on all parameters.
2017-09-06 00:29:18.0345|INFO|AVRCFGGen|Parsing Command Line Arguments...
AVRControlFlowGraphGenerator 1.0.0
Christophe Diericx
ERROR(S):
Required option 'i, input' is missing.
Required option 'o, output' is missing.
-i, --input Required. Input file (.HEX) for which to generate a CFG.
-o, --output Required. Output file (.DOT).
-s, --startaddress (Default: 0) Start Offset (defaults to 0x0).
-d, --dpi (Default: 200) DPI.
--help Display this help screen.
--version Display version information.Generating the Control Flow Graph
The AVRControlFlowGraphGenerator class takes some configuration options in its constructor, and has a single public
GenerateCFG method (return type void) where all the necessary work is performed.
Arguably an object-model graph should be returned here for reusability purposes (with the actual translation into
a dot style graph elsewhere). But for our quick prototype purposes this will do.
public class AVRControlFlowGraphGenerator
{
internal const string LoggerName = "AVRCFGGen";
private static readonly Logger Logger = LogManager.GetLogger(LoggerName);
private AVRControlFlowGraphGeneratorOptions Options { get; }
private AssemblyStatement[] Disassembly { get; set; }
private int HighestOffset { get; set; }
private IDictionary<int,AssemblyStatement> AddressLookup { get; set; }
private IList<BasicBlock> BasicBlocks { get; }
private HashSet<Relation> Relations { get; }
private HashSet<int> VisitedEntryPoints { get; }
private Stack<int> CallStack { get; }
public AVRControlFlowGraphGenerator(AVRControlFlowGraphGeneratorOptions options)
{
Options = options;
AddressLookup = new Dictionary<int, AssemblyStatement>();
BasicBlocks = new List<BasicBlock>();
Relations = new HashSet<Relation>();
VisitedEntryPoints = new HashSet<int>();
CallStack = new Stack<int>(1024);
}
public void GenerateCFG()
{
...
}
}1. Disassembling the HEX file
Using the AVRDisassembler library, disassembling a HEX file (into an array of
AssemblyStatement instances) is a couple of lines of code at most. We will also create a lookup table that allows us to instantly retrieve
an AssemblyStatement at a given logical offset in the code.
// Disassemble
Logger.Info($"Disassembling '{Options.InputFile}'...");
Disassembly = Disassemble(Options.InputFile);
Logger.Trace(
string.Join(
Environment.NewLine,
new []{ "Disassembly:" }.Concat(
Disassembly.Select(x => x.ToString()))
));
// Store highest address
HighestOffset = Disassembly.Last().Offset;
Logger.Debug($"Highest Offset: {HighestOffset}.");
// Create direct address lookup table
Logger.Debug("Creating address lookup table...");
AddressLookup = Disassembly.ToDictionary(stmt => stmt.Offset);private static AssemblyStatement[] Disassemble(string file)
{
var disAssembler = new Disassembler(
new DisassemblerOptions
{
File = file, JsonOutput = false
});
return disAssembler.Disassemble().ToArray();
}
private AssemblyStatement FindEntry(int offset)
{
AddressLookup.TryGetValue(offset, out var result);
if (result == null) throw new InvalidOperationException(
$"Unable to find statement at offset {offset:X8}!");
return result;
}The FindEntry method implementation showcases a few recent additions to the C# language:
- The ability to declare the
outvariable directly (and even implicitely) in the argument list of the method call (as can be seen on the first line ofFindEntry) was introduced in C# 7. - The
$style string interpolation syntax is one of the greatest recent additions in my opinion (introduced in C# 6).
2. Scanning for “Basic Blocks” and mapping “Relations”
As per the Wikipedia definition:
In compiler construction, a basic block is a straight-line code sequence with no branches in except to the entry and no branches out except at the exit.[1][2] This restricted form makes a basic block highly amenable to analysis.[3] Compilers usually decompose programs into their basic blocks as a first step in the analysis process. Basic blocks form the vertices or nodes in a control flow graph.
In our first pass, we will do a depth-first search of the tree:
// First pass: traverse the tree recursively (depth first)
Logger.Info("First pass (traversing the tree)...");
foreach (var block in ParseBlock(Options.StartAddress))
{
Logger.Debug($"Adding <{block}>");
BasicBlocks.Add(block);
}private IEnumerable<BasicBlock> ParseBlock(int startOffset)
{
var stmt = FindEntry(startOffset);
var currentBlock = new BasicBlock();
Logger.Trace($"Visiting {startOffset}..");
VisitedEntryPoints.Add(startOffset);
while (true)
{
currentBlock.Add(stmt);
if (IsBranch(stmt))
{
yield return currentBlock;
var relationsToAdd = new List<Relation>();
Logger.Debug($"Encountered {stmt.OpCode.Name}: {stmt}");
// Unconditional Jumps
if (stmt.OpCode is OpCodes.Branch.JMP)
{
relationsToAdd.Add(
new Relation(startOffset, stmt.Operands.ToArray()[0].Value));
}
else if (stmt.OpCode is OpCodes.Branch.RJMP)
{
var op = stmt.Operands.ToArray()[0];
relationsToAdd.Add(
new Relation(startOffset, stmt.Offset + op.Value + 2));
}
// Conditional Jumps
else if (stmt.OpCode is OpCodes.Branch.BRBC
|| stmt.OpCode is OpCodes.Branch.BRBS)
{
var op = stmt.Operands.ToArray()[1];
relationsToAdd.Add(
new Relation(startOffset, stmt.Offset + op.Value + 2));
relationsToAdd.Add(
new Relation(startOffset, stmt.Offset + 2));
}
// Call And Return
else if (stmt.OpCode is OpCodes.Branch.CALL)
{
relationsToAdd.Add(
new Relation(startOffset, stmt.Operands.ToArray()[0].Value));
CallStack.Push(stmt.Offset + 4);
}
// Return
else if (stmt.OpCode is OpCodes.Branch.RET)
{
var returnTarget = CallStack.Pop();
relationsToAdd.Add(new Relation(startOffset, returnTarget));
}
foreach (var relation in relationsToAdd)
{
var source = relation.Source;
var target = relation.Target;
Logger.Trace($"Adding relation {source} -> {target}");
if (!Relations.Contains(relation)) Relations.Add(relation);
if (VisitedEntryPoints.Contains(target)) continue;
foreach (var block in ParseBlock(target))
yield return block;
}
break;
}
var nextSequentialInstruction = stmt.Offset + stmt.OriginalBytes.Count();
if (nextSequentialInstruction > HighestOffset) break;
stmt = FindEntry(nextSequentialInstruction);
}
}
private static bool IsBranch(AssemblyStatement stmt)
{
return stmt.OpCode is OpCodes.Branch.JMP || stmt.OpCode is OpCodes.Branch.RJMP
|| stmt.OpCode is OpCodes.Branch.BRBC || stmt.OpCode is OpCodes.Branch.BRBS
|| stmt.OpCode is OpCodes.Branch.CALL || stmt.OpCode is OpCodes.Branch.RET;
}Conceptually, what happens here is relatively straightforward:
- We keep adding statements to our current Basic Block until we encounter a Branch instruction:
- Any branching instruction qualifies (please note that not all branching instructions in the
AVRinstruction set are currently supported here). - At that moment, we add a Relation (node edge) between the current Basic Block and the Basic Blocks implicitely started by our Jump Target Offset(s).
- If the Basic Blocks started by our Jump Target Offset(s) have not been visited yet, we (recursively) walk them (and their node edges) next.
- We use a little
Stackstructure in order to keep track of (possibly nested) subroutine calls (and associated returns).
- Any branching instruction qualifies (please note that not all branching instructions in the
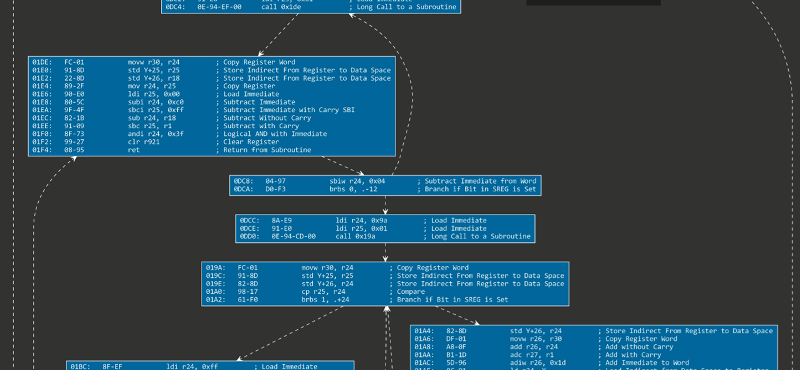
This gives us a reasonable graph already, but a particular problem is still present with this particular algorithm: it is possible a jump brings us at an offset that was already a part of a Basic Block (but not coinciding with either start or end of that particular block).
In that case, we will end up with a graph that is not necessarily incorrect, but will still contain sections of code that are “duplicated”:
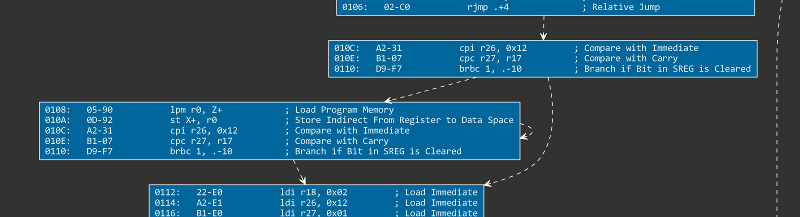
As seen above, Basic Block [010C to 0110] is fully contained within Basic Block [0108 to 0110].
In order to solve this, we want to shrink the larger Basic Block [0108 to 0110] to [0108 to 010A].
Then, we should add a relation from that newly dimensioned block to the existing Basic Block [010C to 0110].
In order to do so, we will issue a second pass of our tree:
// Second pass: find blocks that overlap, and split them
Logger.Info($"Number of Basic Blocks found: {BasicBlocks.Count()}.");
var relationsToRemove = new List<Relation>();
var relationsToAdd = new List<Relation>();
foreach (var block in BasicBlocks)
{
var blockStart = block.FirstOffset;
var blockEnd = block.LastOffset;
foreach (var otherBlock in BasicBlocks.Where(x => x.Guid != block.Guid))
{
var otherBlockStart = otherBlock.FirstOffset;
var otherBlockEnd = otherBlock.LastOffset;
var overlap = blockStart < otherBlockEnd && otherBlockStart < blockEnd;
if (!overlap) continue;
Logger.Trace($"Overlapping blocks found: {block}-{otherBlock}.");
/*
* | +------------+
* | | otherBlock |
* | +------------+ | |
* | | block | | |
* | +------------| +------------+
* \|/
* '
* or
*
* | +------------+
* | | block |
* | | | +------------+
* | | | | otherBlock |
* | +------------| +------------+
* \|/
* '
*/
if (blockEnd == otherBlockEnd && blockStart != otherBlockStart)
{
var biggestBlock = blockStart > otherBlockStart ? otherBlock : block;
var smallestBlock = blockStart > otherBlockStart ? block : otherBlock;
// Shrink the biggest block ...
biggestBlock.RemoveAll(x => x.Offset >= smallestBlock.FirstOffset);
// Move relations of biggest block ...
foreach (var otherRelation in Relations.Where(
x => x.Source == biggestBlock.FirstOffset))
{
relationsToRemove.Add(otherRelation);
relationsToAdd.Add(
new Relation(smallestBlock.FirstOffset, otherRelation.Target));
}
// ... and add a new relation
relationsToAdd.Add(
new Relation(biggestBlock.FirstOffset, smallestBlock.FirstOffset));
}
else
{
throw new NotImplementedException();
}
// Remove relations
foreach (var relationToRemove in relationsToRemove)
Relations.Remove(relationToRemove);
// Add relations
foreach (var relationToAdd in relationsToAdd)
if (!Relations.Contains(relationToAdd))
Relations.Add(relationToAdd);
}
}After issuing the second pass, the problematic snippet above will look correct:
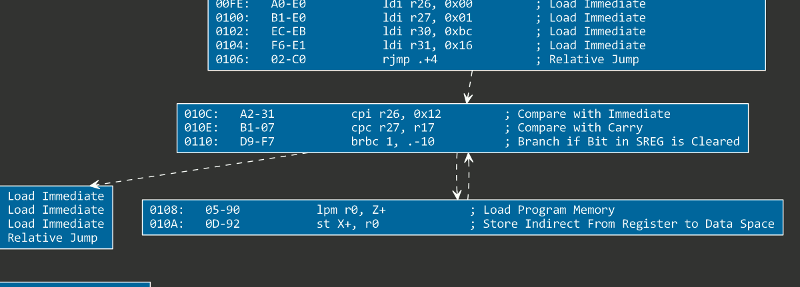
3. Generating the .DOT file
Generating the graph file in the DOT language mostly consists of adding
our nodes (“Basic blocks”) and node edges (“Relations”) and applying some styling.
// Generate graph
var graphBuilder = new StringBuilder();
graphBuilder.AppendLine("digraph G {");
graphBuilder.AppendLine($" graph[dpi={Options.DPI},bgcolor=\"#333333\",fontcolor=\"white\"];");
graphBuilder.AppendLine(" node[style=filled,shape=box,fontcolor=\"white\",color =\"white\",fillcolor=\"#006699\",fontname=\"Consolas\"];");
graphBuilder.AppendLine(" edge[style=dashed,color=\"white\",arrowhead=open];");
foreach (var block in BasicBlocks)
graphBuilder.AppendLine(
$" \"{FormatBlock(block.FirstOffset)}\" "
+ $"[label=\"{FormatContents(block.ToArray())}\"];");
foreach (var relation in Relations)
graphBuilder.AppendLine(FormatRelation(relation));
graphBuilder.AppendLine("}");
var graph = graphBuilder.ToString();
File.WriteAllText(Options.OutputFile, graph);private static string FormatRelation(Relation relation)
{
return $" \"{FormatBlock(relation.Source)}\" -> \"{FormatBlock(relation.Target)}\";";
}
private static string FormatBlock(int startOffset)
{
return $"Block_{startOffset:X8}";
}
private static string FormatContents(IEnumerable<AssemblyStatement> statements)
{
return string.Join(@"\l",
statements.Select(x => x.ToString()).Concat(new[] { string.Empty }));
}Once the .DOT file is generated, we can convert it to another format (e.g. PNG, SVG, …) using
the dot command line tool (part of the GraphViz installation, available on many platforms):
dot MyFile.dot -Tpng -o MyFile.pngSample Output
Here is some sample output (based on the Blink program in the Arduino code example section):
{kind=link}
Zoomed out rendered graph:
